Adopting OMERO for your microscopy data
Guillaume Gay, CENTURI
Novembre 2020
Why?
Microscopy data is big and complex
- Long experiments
- Screens (maybe not here)
- Data intensive microscopes (e.g. Light sheet)
- Complicated data (super-res, speckle)
Need to organize both data and metadata
Keeping data accessible
(for you and others)
- A file browser is not a data management tool
- Enforcing standards within your group can be hard
- What happens when students / post-doc are gone?
- Collaboration with data-scientist can be a challenge
Data management plan
- Mandated by institutions or the ANR (since last year)
- As open as possible, as closed as necessary
- Here is a template
FAIR
Findable
Accessible
Interoperable
Re-usable data
What?
Some history
- 1990s first commercial CCD
- 2000-2010 the Metamorph era (and nd / stk files)
- 2005 sq. formats explosion (vendor lock-in strategy)
- since 2010 :
- change of paradigm regarding open-source,
- federation of global microscopy community
Openmicroscopy provides standards
- Managed by the U. of Dundee group / Glencoe software (Jason Swedlow, Josh Moore)
- Defined OME-TIFF (data + metadata in a single file)
- created BioFormats
- Omero is also used in the industry (CROs, Perkin Elmer)

- one server / multiple clients
- user groups / permission granularity
Dataflow







raw data is not (necessarily) copied
Data Federation
At the University, National and International levels

Features overview
Webclient
Search and Annotations
- Readily available: search over names
- Annotations are harder
- Cards based annotations
Fiji Plugin
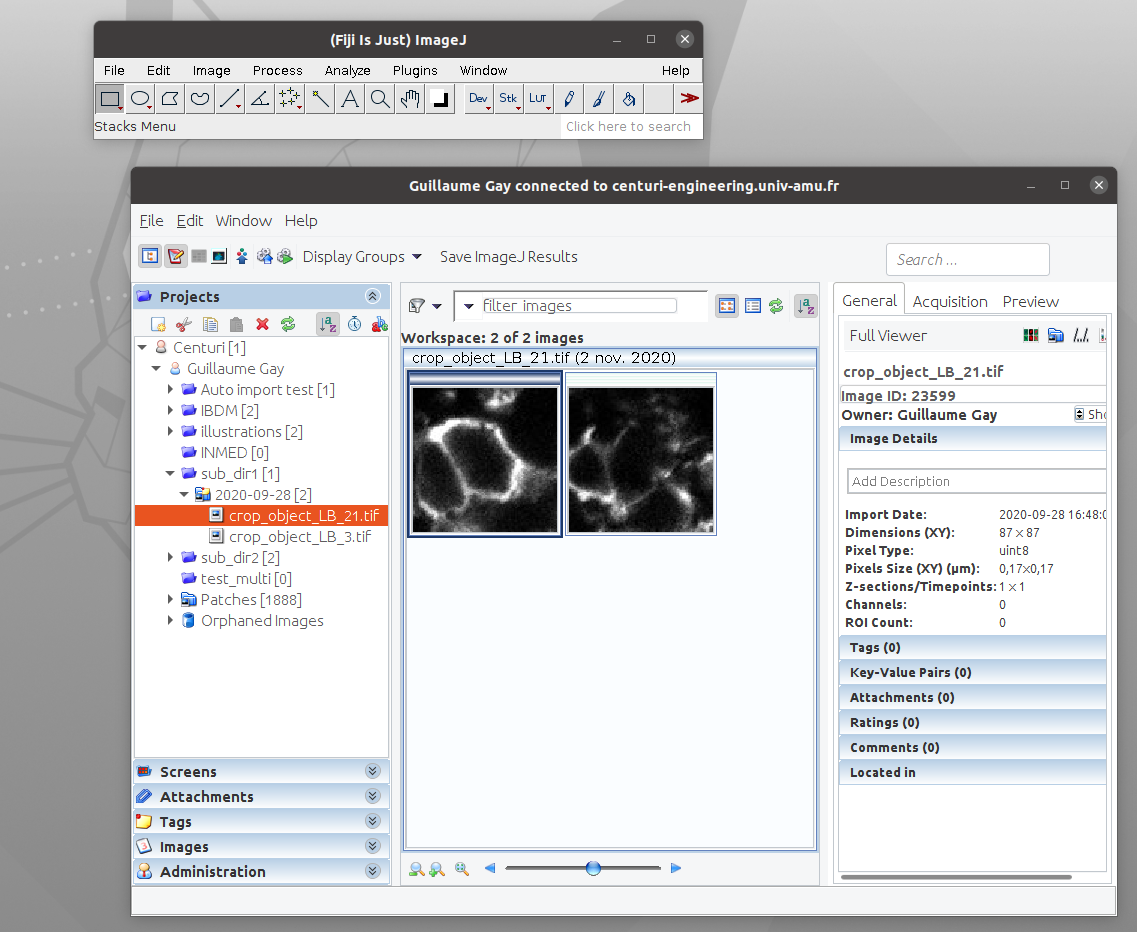
How and when?
Costs
- One server (less than 3k€)
- Mainly HR
HR implications
Research engineer @ 50% FTE (centuri):
- manage the federated databases
- interface with data analysts
- custom dev
In each institute:
- Training session
- Referee for user management / on site admin
- A “backup” sysadmin
When?
Setup step (first trimester 2021)
- Renew list of personnel, access to disks
- Automated import strategy (old data)
- Automated import strategy (new data)
- Automated annotation ?
Usage and adoption (throughout 2021)
- Training of post-docs & PhDs
- Freezing of the production workflow
Conclusion
- Findable : through filenames, annotations
- Accessible : publish & share from the web client
- Interoperable : download in a standard format
- Re-usable : tracked metadata